AI recommendations look random. At scale, they reveal patterns.
We ran 4,800 tests across ChatGPT, Gemini, Claude, and Perplexity to understand the patterns AI keeps repeating when recommending local businesses.
People are not just searching on Google anymore. They are asking AI: “best plumber near me,” “good dentist in Manchester,” “emergency boiler repair tonight.”
And AI gives them a direct answer. Sometimes one name. Sometimes a small handful. Either way, there is no page two.
When someone asks AI for a recommendation, it often names a business — or a small handful. If you are not in that answer, you do not exist in that moment. You never see the customer you just lost, because they never reached you in the first place.
That is why we built AI Rank. And that is why we ran 4,800 AI recommendation tests across four major platforms, recorded 19,810 individual recommendations, and analysed over 768,000 words of AI reasoning to find out what stays consistent when the answers keep changing.

of businesses appeared exactly once.
Ask ChatGPT for the best plumber in Bristol right now. Ask again in an hour. You will get a completely different list.
In our study, AI produced 19,810 individual business recommendations. Of the 3,583 unique businesses that appeared, nearly two-thirds showed up in a single test and were never mentioned again. That is not a glitch. It is how large language models work.
This is why tools that check once and give you a score are selling you a snapshot that is already out of date.


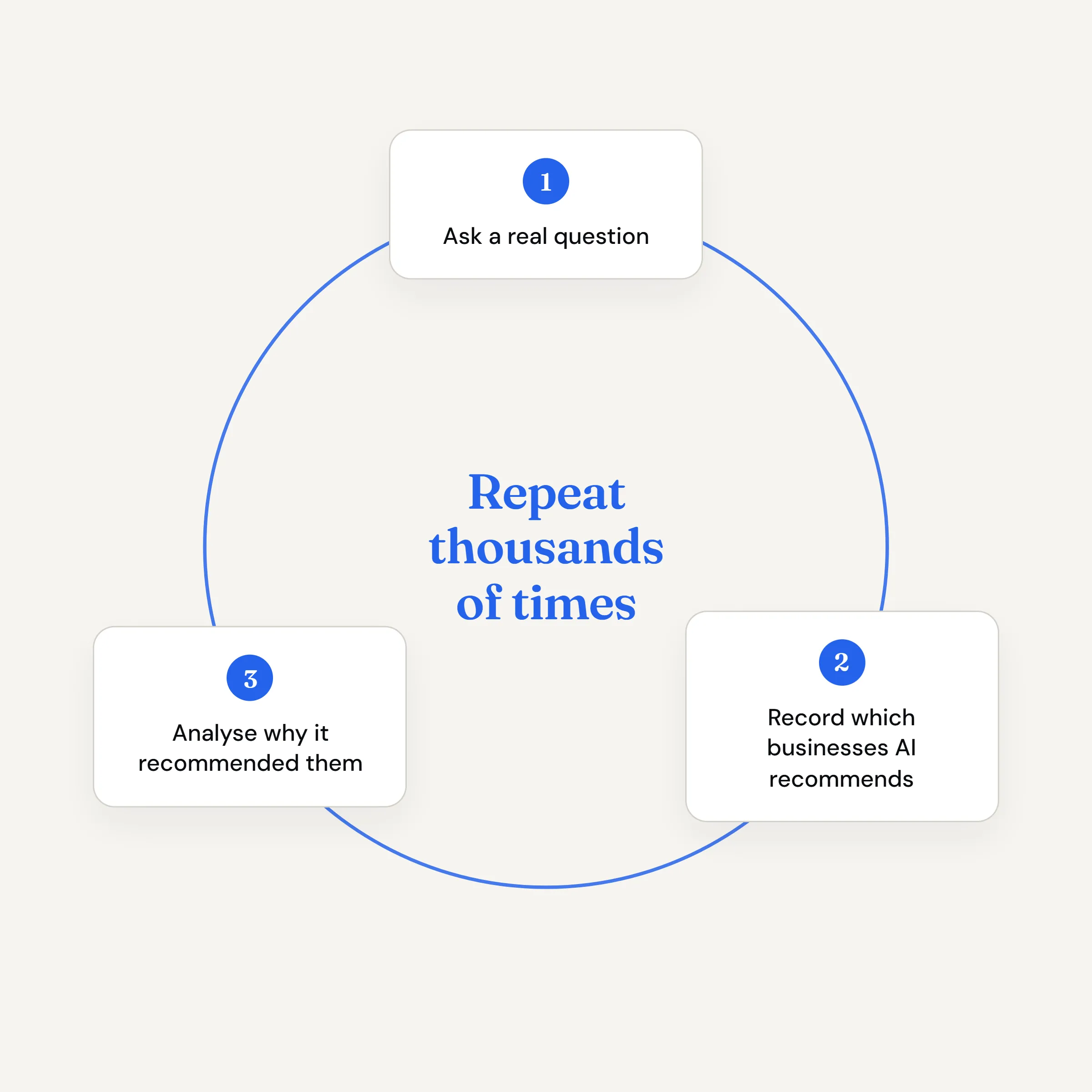
Real questions, asked thousands of times.
We ask AI the same kinds of questions your customers ask. Not once. Not ten times. Hundreds of times across every major platform, using 100 different questions across Brighton, Bristol, and Manchester — phrased in every way a real person would ask them. City names, postcodes, neighbourhoods, and “near me” queries.
Each time, we record which businesses AI recommends. Then we ask it why. Then we do it all again, until the patterns become undeniable.
The names change. The patterns repeat.
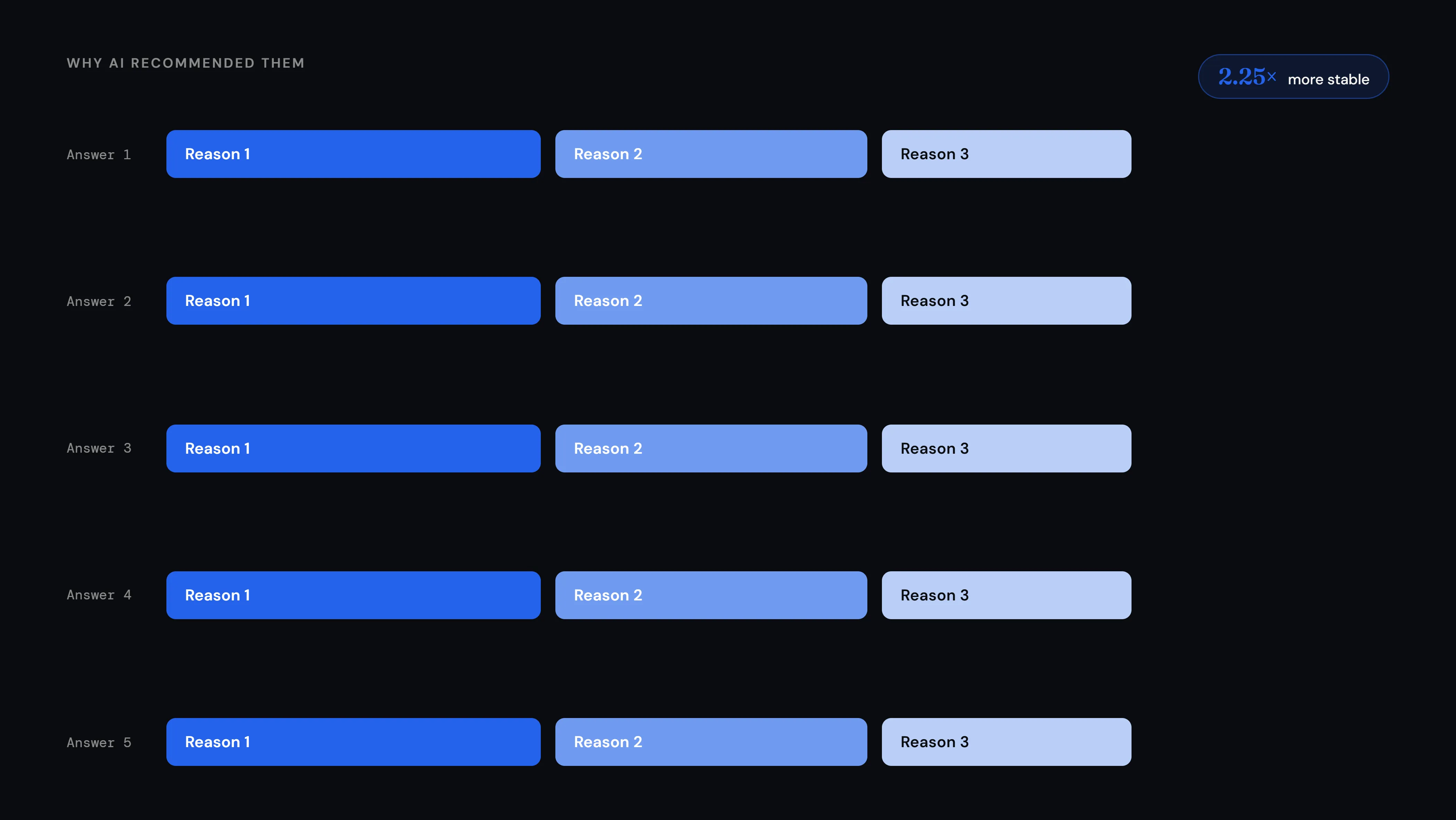
We did not just track which businesses AI recommended. We analysed 768,000 words of AI reasoning to understand what kept coming back.
Across 4,800 tests, the businesses AI recommended changed constantly. But the signals AI kept mentioning when explaining those recommendations were 2.25 times more stable than the business lists themselves.
In fact, 99.9% of AI responses mentioned at least one of the same recurring signals. The same kinds of reasons kept appearing, across every platform, every city, every question:
- Local presence and relevance
- Authority and trusted credentials
- Clear, specific service descriptions
- Reviews and reputation
- Directory and platform listings
- Depth and quality of content
Technical signals like structured data and schema markup appeared far less often. We still treat them as good practice, but they are not the main lever.
You cannot predict who AI will recommend. But you can strengthen the signals it keeps mentioning.
If the same signals keep appearing across thousands of tests, they give you a practical place to focus. Not by gaming the system, but by making your business clearer, stronger, and easier to verify online.
- Stop chasing the chaos. AI will recommend different businesses tomorrow. Tracking exact “rankings” is chasing noise.
- Focus on the recurring signals. If AI keeps mentioning reviews, directory presence, and clear service pages when recommending your competitors, those are the gaps to close.
- Act on the action plan. We extract the recurring patterns, find where your business falls short, and tell you what to fix first.
Tested across every major AI platform.
We do not test one AI and assume the rest agree. Every test runs across ChatGPT, Gemini, Claude, and Perplexity — 1,200 tests per platform, all hitting the provider directly.
The pattern holds across all of them. Different platforms, different models, same result: the reasoning patterns are far more consistent than the business lists.

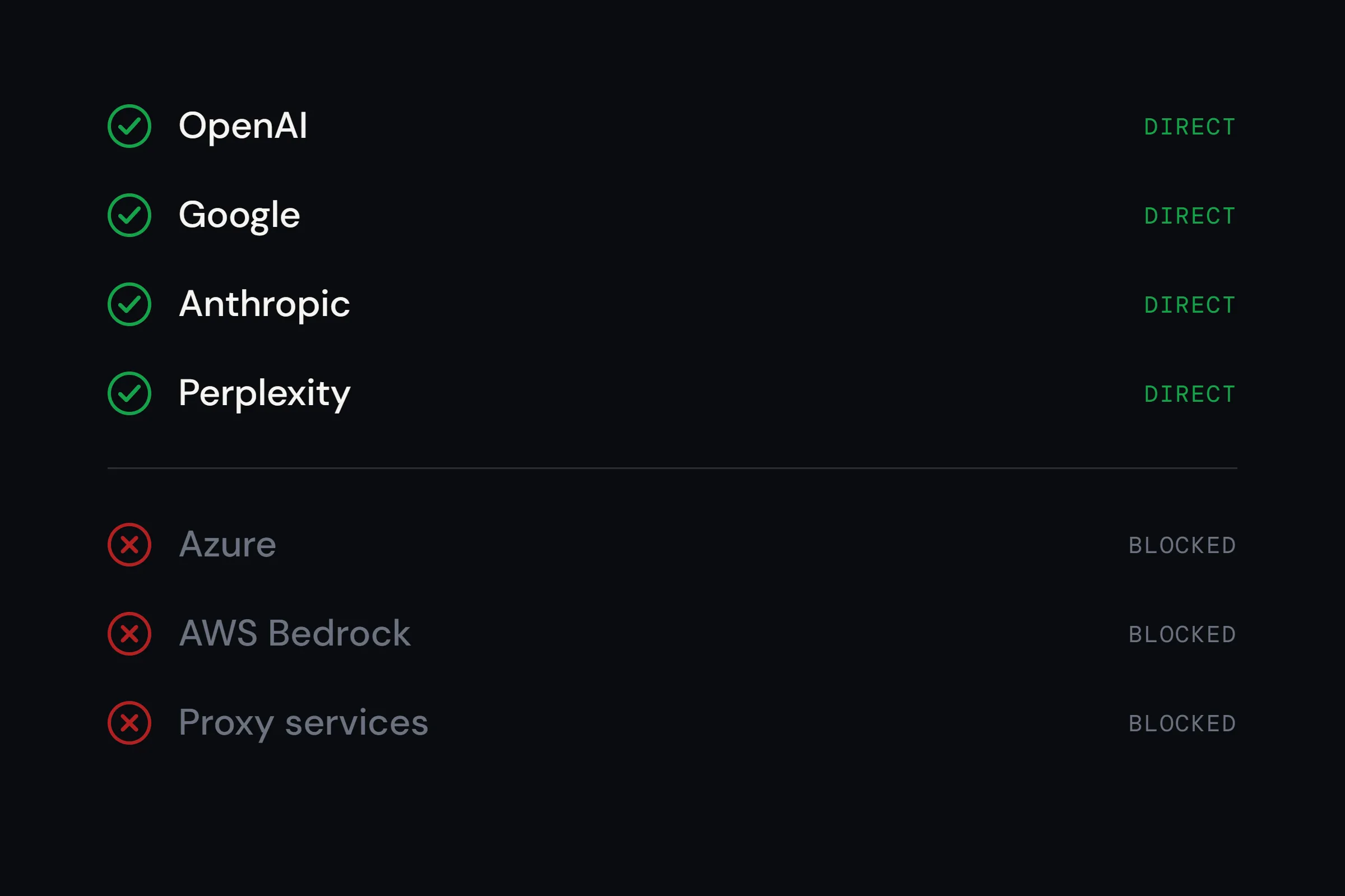
Direct first-party API testing. No proxies.
We verify which provider served every request. Every test hits the AI provider directly — OpenAI, Google, Anthropic, Perplexity. We record the model, provider, and routing metadata so our benchmarks are never silently mixed across routes.
When you act on our data, you know which provider produced it — no silent substitutions.
The detail behind the data.
If you are evaluating AI Rank for your agency or your clients, here is the technical summary.
| What we test | How |
|---|---|
| Platforms | ChatGPT, Gemini, Claude, Perplexity |
| Prompt types | Real local recommendation questions customers actually ask |
| Location contexts | Explicit city, neighbourhood, postcode, and spatial “near me” context |
| Repeats | Multiple runs per prompt combination |
| Analysis | Recommendation list + follow-up reasoning + signal classification |
| Output | Appearance frequency, competitor patterns, recurring recommendation signals |
| Verification | Direct first-party API confirmed on every request |
We measure the baseline, not the noise.
When a consumer asks ChatGPT for a recommendation, the answer is shaped by their location, search history, and conversation context. That personalisation is unpredictable — no tool can or should try to replicate it.
We measure baseline recommendation behaviour: what appears when the AI has the prompt and the location context, but no personal history from the user. This is the foundation every personalised response is built on.
If your business is weak in the baseline, you are relying on personalisation to rescue you — and that is not a strategy.
Honest about what this is, and what it is not.
- We do not claim AI has fixed rankings.
- We do not claim to recreate every personalised consumer session.
- We do not claim these are guaranteed ranking factors.
- We measure repeated recommendation behaviour and the signals AI consistently mentions when explaining its choices.
If someone tells you they know exactly how to rank in ChatGPT, they are guessing. We measure patterns at scale and let the data speak for itself.
Check your AI discoverability.
Run a free AI discoverability check. Find out whether AI can clearly find your business, which competitors look stronger online, and what to improve first.
Run the free check →